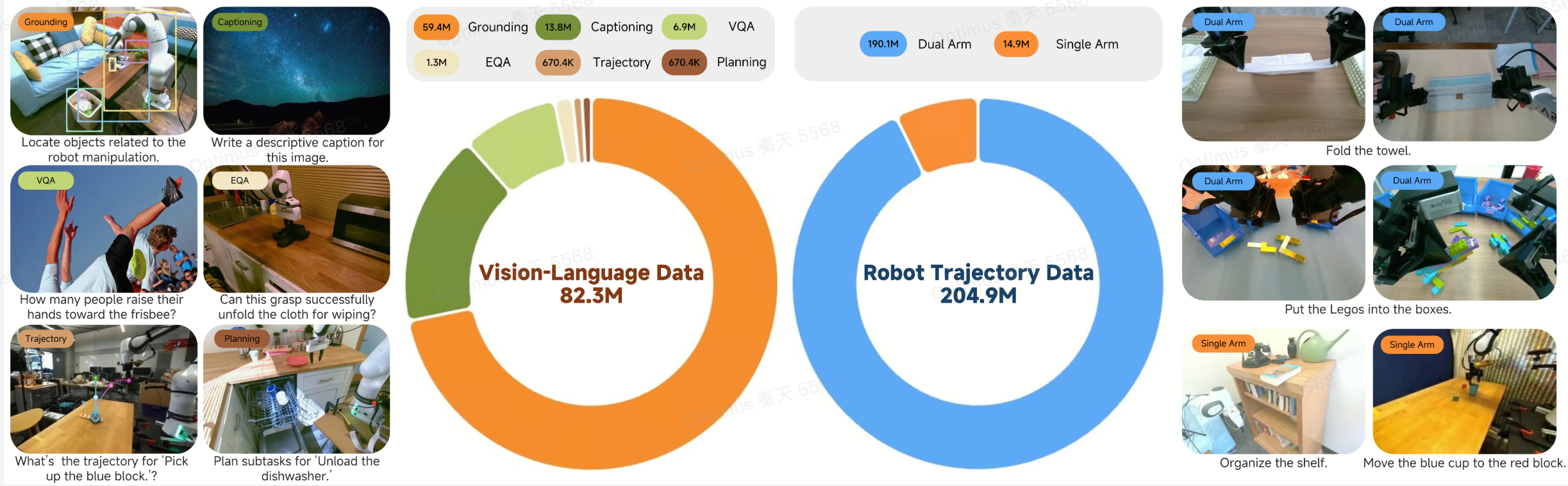
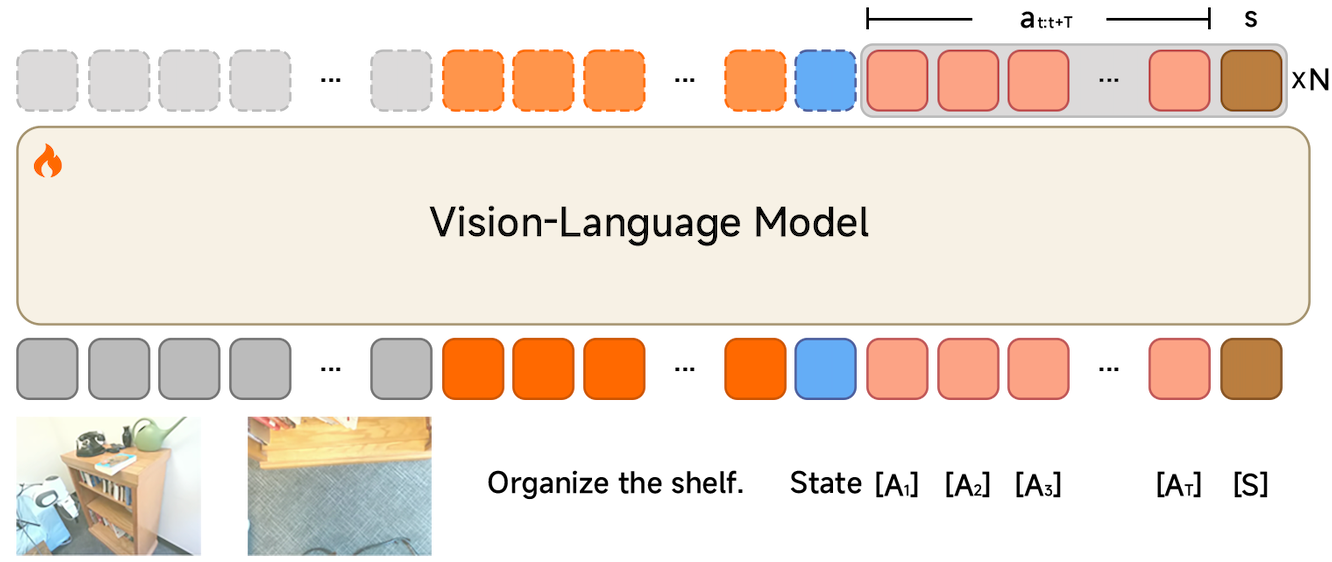
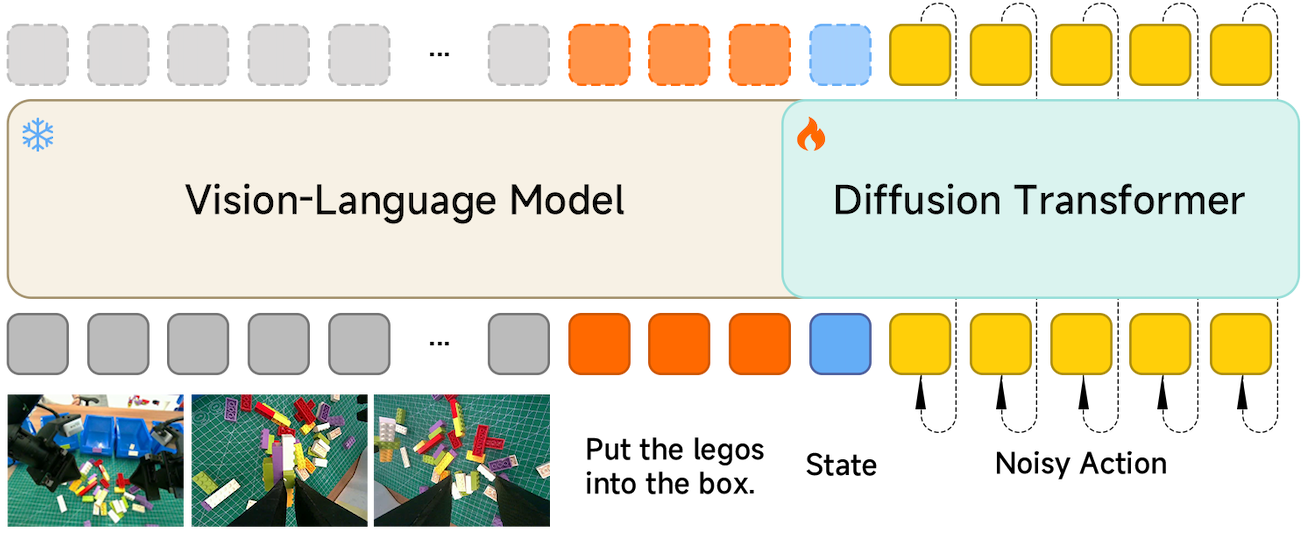
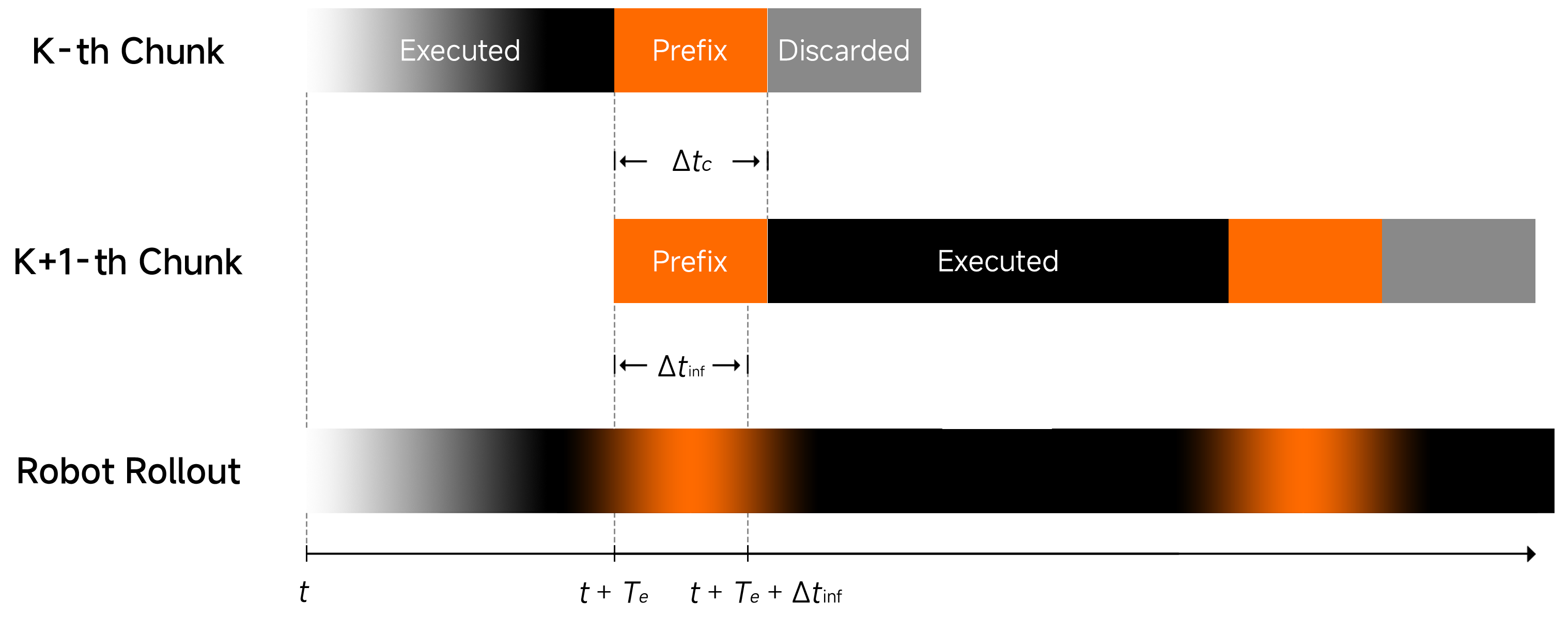
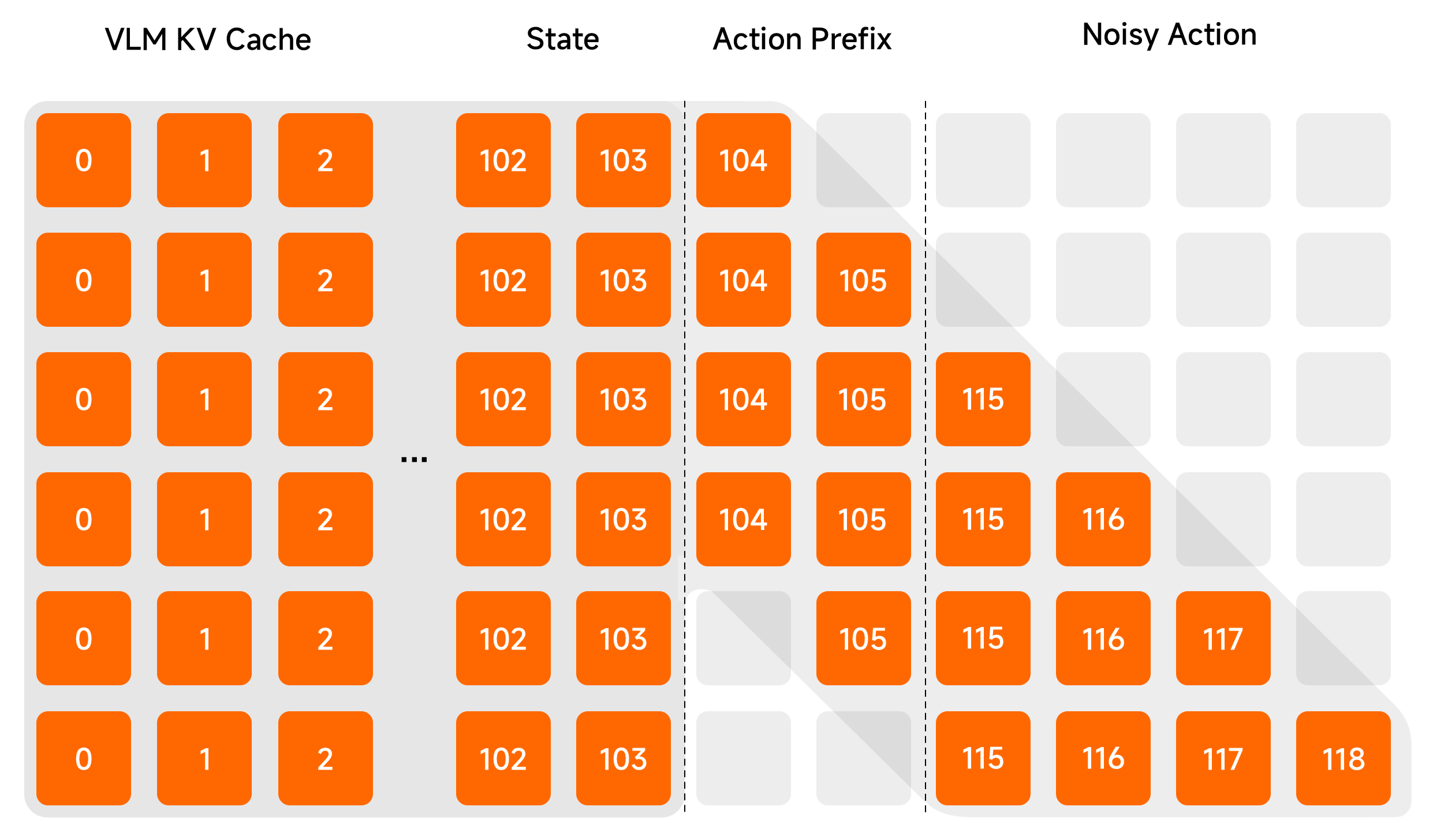
Results
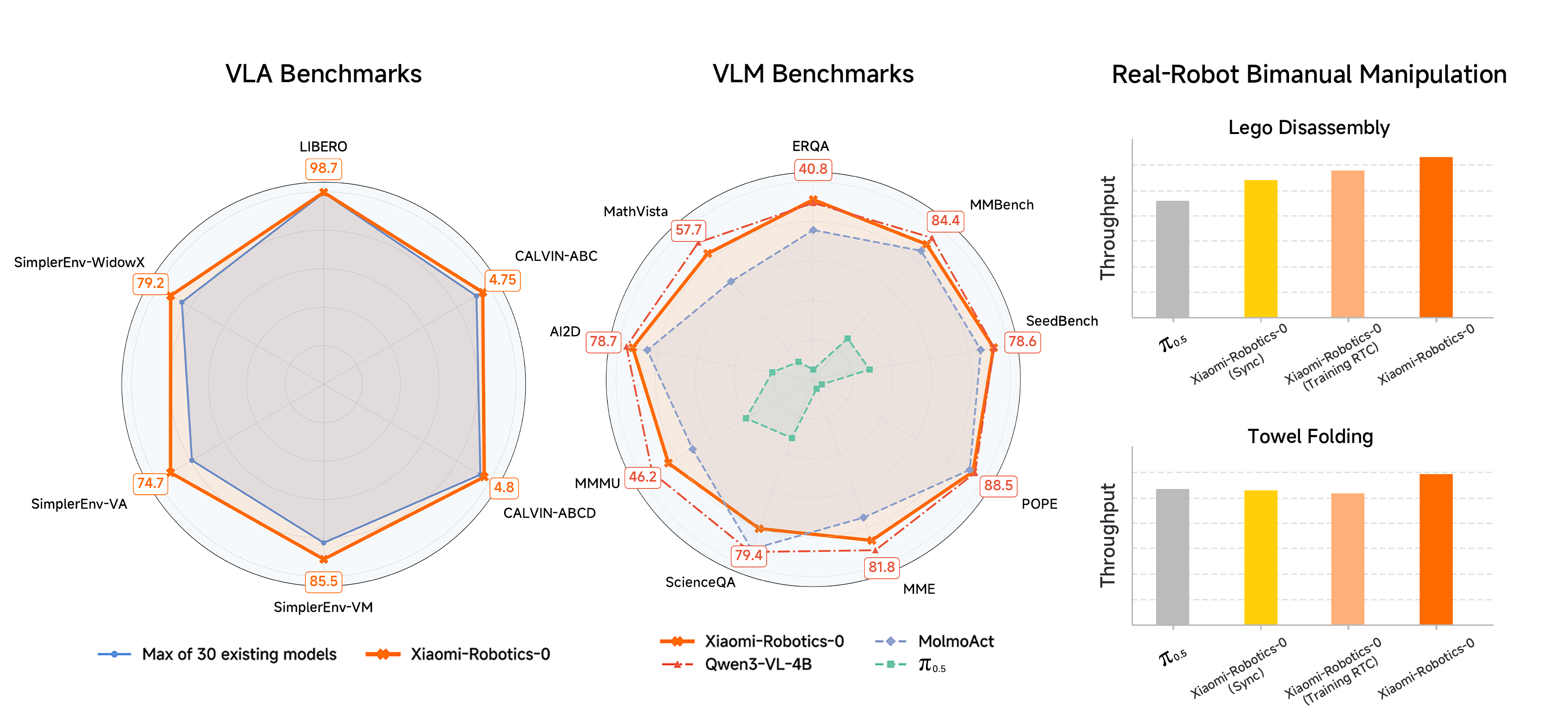
Xiaomi-Robotics-0 achieves state-of-the-art performance across three simulation benchmark. Specifically, it achieves an average success rate of 98.7% on LIBERO. On SimplerEnv, it delivers strong performance under Visual Matching (85.5%) , Visual Aggregation (74.7%), and WidowX (79.2%). On CALVIN, it attains an average length of 4.75 and 4.80 on the ABC-D and ABCD-D split, respectively. On VLM benchmarks, our pre-trained model matches the performance of the underlying pre-trained VLM. In real-robot evaluations, Xiaomi-Robotics-0 achieves high success rates and strong throughput on two challenging bimanual manipulation tasks, Lego Disassembly and Towel Folding.